In general, there is always confusion between TCO and ROI. TCO is the Total Cost of Ownership and a component of ROI. TCO helps businesses focus on their core competencies and reduces the load on the IT department. When IT companies came out with the concept of managed services, they started looking at outsourcing their IT department’s functions to IT service providers. However, they retained minimal IT department resources and started reducing the Total cost of ownership. Cots products gave away inhouse resources of the IT department and further reduced the TCO. However, the real TCO reduction started when the cloud came into the picture. It totally reduced the capex cost and moved the infrastructure from the premises to a third-party premise. ROI on the other hand focuses not just on removing capex costs but also gives a return on investment for the customer. Let us look at the parameters that impact the ROI on the cloud.
1. Downtime: The single most important parameter that could possibly affect the return on investment is the downtime that happens across the IT systems. It affects customers, affects internal stakeholders and so on. Due to extensive experience, the public cloud service providers have drastically reduced the downtime due to Hardware Infrastructure. The second biggest reason for incidents is the application infrastructure. The cloud service providers not only abstracted out the hardware for the users but also abstracted the application infrastructure namely web servers, application servers, cache management, container management, application deployment and all these too. There were issues in deployment without a rollback plan. All the public cloud service providers apart from providing just hardware provided managed services for application infrastructure. Effectively downtime hours had been reduced by the cloud service providers both due to hardware as well as application infrastructure.

2. Agility: Agility is the ability to move quickly and easily. IT departments have been slow on deployments for the changes required by the business as the primary change is not only in the development code but the workflow that needs to change. The cloud service providers have got flexible workflows for deployment by bringing DevOps infrastructure into the cloud. The DevOps infrastructure of the cloud service provider provides Code Repository, Automatic Build, Automatic Deployment, and rollbacks followed by quick monitoring.
Autoscaling is an important parameter that is affecting agility. Quick provisioning of compute engines, creating security policies and attaching it to the compute engines, ability change at one place that gets reflected everywhere and so on. While Agility cannot be exactly defined in hours, the flow disruption occurs due to lack of agility.
3. Pay for what you use: In a traditional data centre model the resources are there even if you do not use it. A onetime irreversible budget was created. Irreversibility is the biggest issue in capex buying. There will be many idle resources and the capacity prediction has been a big problem. Cloud service providers solve all the problems of underutilized and over-provisioned resources. Hygiene issues can be automated. Resource usages are completely automated.
4. Technology deprecation: Every advancement in technology leads to cost reduction or capacity enhancement at a lower price. The cost of upgrading technology in a data centre environment is enormous. The process of doing POC, pilot and production is a long-driven process. However, public cloud service providers make it easy.
The final equation for ROI is always in terms of money. Converting the above tangible and intangible parameters into time lost or gained is important to calculate the return on investment. The ROI Equation will have an investment component. It has a traditional investment component as well. So, a simple way to calculate cloud ROI is as follows,
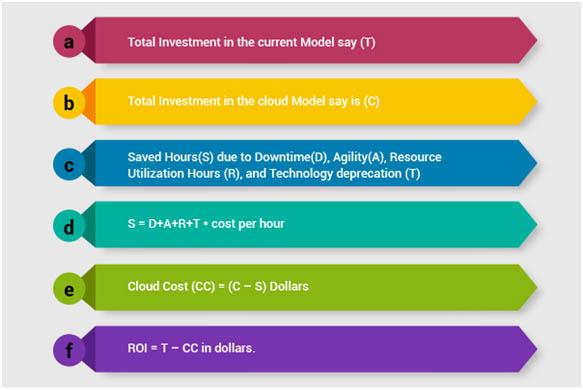
Note: The step no (c) is the most difficult parameter to arrive at to deliver ROI.